Web Scraping Using Selenium And Python
Content
Web Scraping Using Selenium And Python
Selenium is used for Javascript featured web sites – and can be used as a standalone net scraper and parser. They are all helpful in their own way, and studying tips on how to use all of them will make you a greater web scraping developer. In order to make this project work you need to have a profile in your browser the place you already scanned the QR along with your account then we are going to use that account for launching the Selenium driver. A major element right here, something that the majority blogs and tutorials on Selenium will address, is the WebDriver (pictured here). The WebDriver, should you’re scripting this code from scratch, have to be imported and assigned with your browser of alternative.
Locating Elements
Depending on the policies of the web scraper, technical workarounds may or is probably not employed. Python has turn into the most well-liked language for net scraping for a variety of reasons. Python has turn into some of the well-liked web scraping languages due partly to the varied web libraries which were created for it.
Find_element
As troublesome projects go, although, it is an easy package to deploy within the face of challenging JavaScript and CSS code. First I used BeautifulSoup and Mechanize on Python however I noticed that the web site had a button that created content material via JavaScript so I determined to use Selenium. Web crawling and knowledge extraction is a ache, especially on JavaScript-based mostly sites.
Webelement
If you do determine your state of affairs merits utilizing Selenium, use it in headless mode, which is supported by (at least) the Firefox and Chrome drivers. It was an extended course of to comply with however I hope you found it fascinating. Ultimately in the end LinkedIn, like most different websites, is fairly straight forward to scrape data from, particularly using the Selenium tool. With the Selenium Nodes you could have the ability of a full-blown browser mixed with KNIME’s processing and data mining capabilities. We might be utilizing the ipython terminal to execute and test every command as we go, instead of getting to execute a .py file. Within your ipython terminal, execute each line of code listed beneath, excluding the feedback. We will create a variable "driver" which is an occasion of Google Chrome, required to carry out our instructions. For this task I might be utilizing Selenium, which is a tool for writing automated tests for internet purposes.
Explode your B2B sales with our Global Vape Shop Database and Vape Store Email List. Our Global Vape Shop Database contains contact details of over 22,000 cbd and vape storeshttps://t.co/EL3bPjdO91 pic.twitter.com/JbEH006Kc1
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
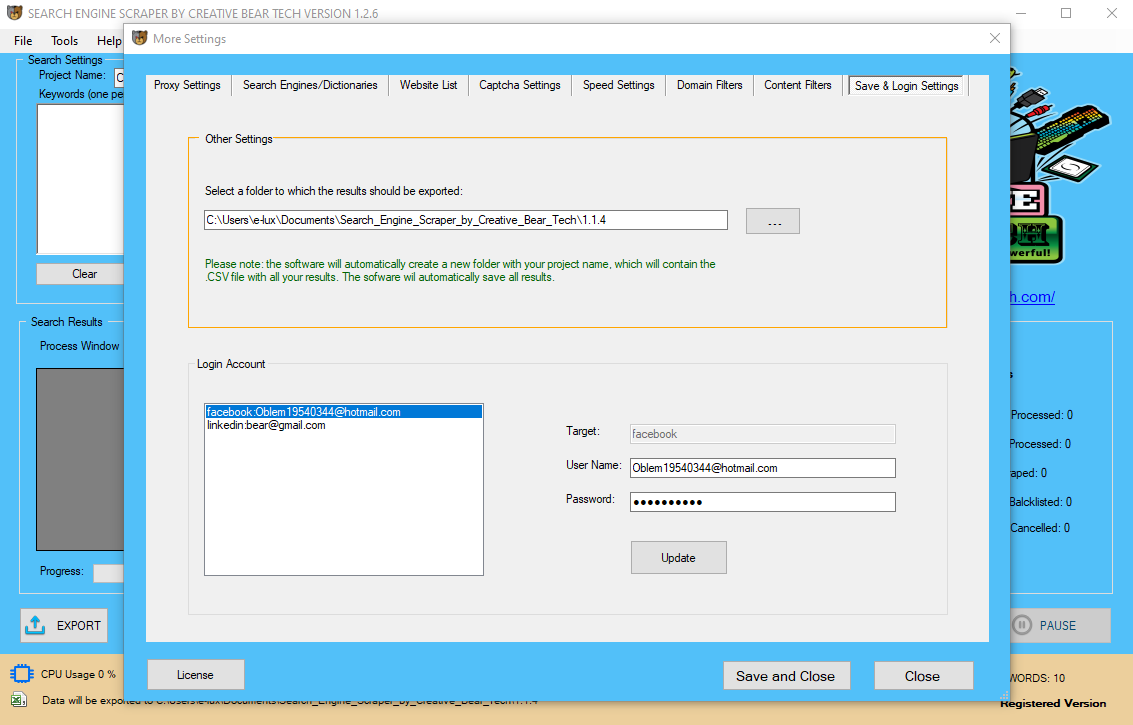
 Unlike the opposite libraries, Selenium wasn’t originally designed for web scraping. First and foremost, Selenium is an online driver designed to render web pages like your web browser would for the aim of automated testing of web purposes. I would recommend using Selenium for things corresponding to interacting with web pages whether it is in a full blown browser, or a browser in headless mode, corresponding to headless Chrome.
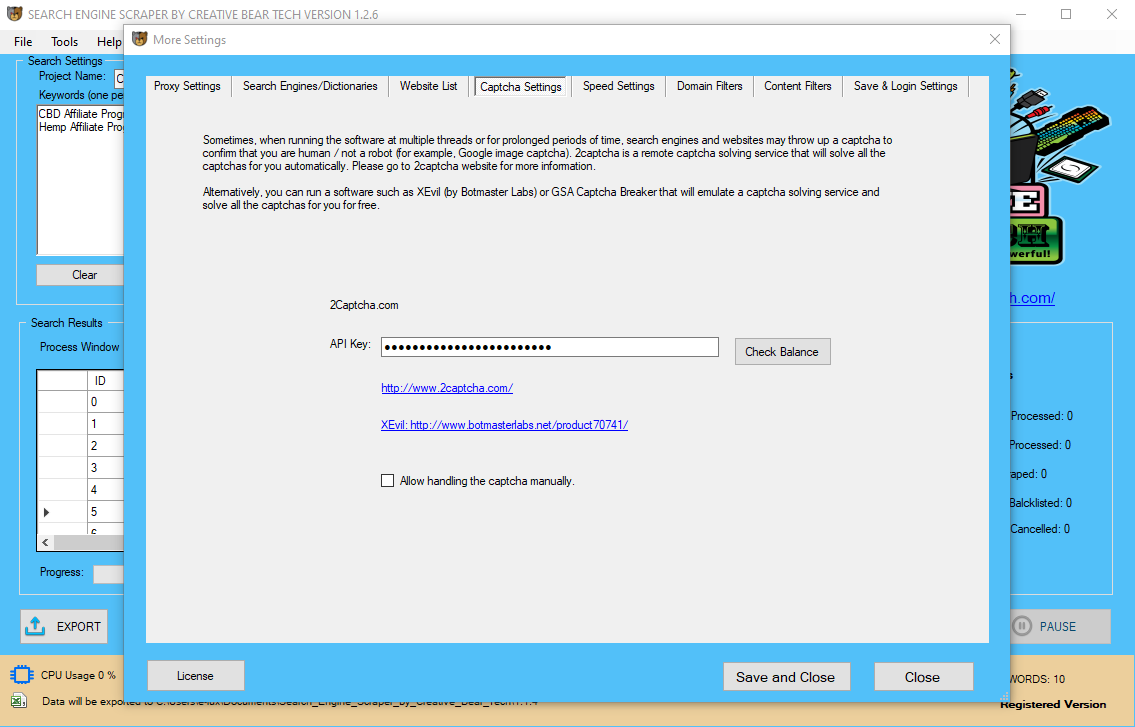
Unlike the opposite libraries, Selenium wasn’t originally designed for web scraping. First and foremost, Selenium is an online driver designed to render web pages like your web browser would for the aim of automated testing of web purposes. I would recommend using Selenium for things corresponding to interacting with web pages whether it is in a full blown browser, or a browser in headless mode, corresponding to headless Chrome.  When this feature is chosen, you can merely choose the language (Python in our case) and save it to your project folder. When you open the file you get a fully functioning Python script. As it mimics a consumer and interacts with the entrance facing parts of an internet page, it could possibly simply determine the mandatory Java Script or CSS code and provide the right path to get you what you need. This is so the subsequent link in the loop will be out there to click on on the job listing web page. The python_button.click on() above is telling Selenium to click on the JavaScript link on the page. After arriving at the Job Titles page, Selenium arms off the page source to Beautiful Soup. The Selenium package deal is used to automate net browser interplay from Python. Gigi Sayfan is a principal software program architect at Helix — a bioinformatics and genomics begin-up. His technical experience contains databases, low-level networking, distributed techniques, unorthodox consumer interfaces, and common software program improvement life cycle. Beautiful Soup is a Python library constructed particularly to pull information out of HTML or XML files. Web browser Web driver hyperlink Chrome chromedriver Firefox geckodriver Safari safaridriver I used chromedriver to automate the google chrome internet browser. The following block of code opens the web site in seperate window. Selenium python API requires an online driver to interface together with your choosen browser. The corresponding internet drivers may be downloaded from the following hyperlinks. And lastly, when you are scraping tables full of data, pandas is the Python knowledge evaluation library that may handle it all. In distinction, when a spider built utilizing Selenium visits a page, it will first execute all the JavaScript available on the web page earlier than making it obtainable for the parser to parse the info. The advantage to this strategy is that it enables you to scrape information not obtainable with out JS or a full browser. However, the online scraping course of is much slower in comparison with a easy HTTP request to the online browser because the spider will execute all the scripts current on the web page. After inspecting the elements on the web page these URLs are contained inside a "cite" class. However, after testing within ipython to return the record length and contents, I seen that some advertisements were being extracted, which additionally embrace a URL within a "cite" class. In the early days, scraping was primarily done on static pages – these with known elements, tags, and knowledge. In order to collect this data, you add a way to the BandLeader class. Checking back in with the browser’s developer instruments, you discover the right HTML elements and attributes to select all the information you want. Also, you solely wish to get information about the currently playing track if there music is definitely playing on the time. This information will clarify the method of building an online scraping program that can scrape information and download recordsdata from Google Shopping Insights. Web scraping with Python and Beautiful Soup is a superb device to have inside your skillset. Use internet scraping when the information you need to work with is on the market to the public, but not necessarily conveniently available. When JavaScript provides or “hides” content, browser automation with Selenium will insure your code “sees” what you (as a person) should see. However, if speed is an enormous concern for you otherwise you plan to scrape the net scale, then executing the JavaScript on every net web page you go to is completely impractical. You’ll need to take a much more refined strategy to scraping the net. This performance is beneficial for net scraping as a result of lots of today’s trendy web pages make intensive use of JavaScript to dynamically populate the page. The downside this causes for regular web scraping spiders is most of them don’t execute this JavaScript code. Which prevents them from accessing all of the available information, limiting their capacity to extract all the obtainable knowledge. For this example, we'll be extracting data from quotes to scrape which is specifically made to practise internet scraping on. We'll then extract all of the quotes and their authors and store them in a CSV file. In addition to this, they supply CAPTCHA handling for you as well as enabling a headless browser so that you'll look like an actual person and never get detected as a web scraper. For more on its usage, check out my submit on net scraping with scrapy. In the primary a part of this collection, we introduced ourselves to the concept of net scraping utilizing two python libraries to attain this task. Web scraping utilizing Selenium and BeautifulSoup could be a useful tool in your bag of Python and information data tips, especially whenever you face dynamic pages and heavy JavaScript-rendered websites. This information has coated just some aspects of Selenium and web scraping. Our instruments might be Python and awesome packages like requests, BeautifulSoup, and Selenium. The third option is to make use of a self-service point-and-click on software program, corresponding to Mozenda. Selenium is a special software when compared to BeautifulSoup and Scrapy. It automates net browsers, and you should use it to carryout actions in browser environments in your behalf. With Selenium, you can pull out data from an HTML document 21 Lead Generation Software For B2B Businesses To Use in 2020 as you do with Javascript DOM API. Via Selenium’s API, you'll be able to truly export the underlying code to a Python script, which might later be used in your Jupyter Notebook or textual content editor of alternative.
When this feature is chosen, you can merely choose the language (Python in our case) and save it to your project folder. When you open the file you get a fully functioning Python script. As it mimics a consumer and interacts with the entrance facing parts of an internet page, it could possibly simply determine the mandatory Java Script or CSS code and provide the right path to get you what you need. This is so the subsequent link in the loop will be out there to click on on the job listing web page. The python_button.click on() above is telling Selenium to click on the JavaScript link on the page. After arriving at the Job Titles page, Selenium arms off the page source to Beautiful Soup. The Selenium package deal is used to automate net browser interplay from Python. Gigi Sayfan is a principal software program architect at Helix — a bioinformatics and genomics begin-up. His technical experience contains databases, low-level networking, distributed techniques, unorthodox consumer interfaces, and common software program improvement life cycle. Beautiful Soup is a Python library constructed particularly to pull information out of HTML or XML files. Web browser Web driver hyperlink Chrome chromedriver Firefox geckodriver Safari safaridriver I used chromedriver to automate the google chrome internet browser. The following block of code opens the web site in seperate window. Selenium python API requires an online driver to interface together with your choosen browser. The corresponding internet drivers may be downloaded from the following hyperlinks. And lastly, when you are scraping tables full of data, pandas is the Python knowledge evaluation library that may handle it all. In distinction, when a spider built utilizing Selenium visits a page, it will first execute all the JavaScript available on the web page earlier than making it obtainable for the parser to parse the info. The advantage to this strategy is that it enables you to scrape information not obtainable with out JS or a full browser. However, the online scraping course of is much slower in comparison with a easy HTTP request to the online browser because the spider will execute all the scripts current on the web page. After inspecting the elements on the web page these URLs are contained inside a "cite" class. However, after testing within ipython to return the record length and contents, I seen that some advertisements were being extracted, which additionally embrace a URL within a "cite" class. In the early days, scraping was primarily done on static pages – these with known elements, tags, and knowledge. In order to collect this data, you add a way to the BandLeader class. Checking back in with the browser’s developer instruments, you discover the right HTML elements and attributes to select all the information you want. Also, you solely wish to get information about the currently playing track if there music is definitely playing on the time. This information will clarify the method of building an online scraping program that can scrape information and download recordsdata from Google Shopping Insights. Web scraping with Python and Beautiful Soup is a superb device to have inside your skillset. Use internet scraping when the information you need to work with is on the market to the public, but not necessarily conveniently available. When JavaScript provides or “hides” content, browser automation with Selenium will insure your code “sees” what you (as a person) should see. However, if speed is an enormous concern for you otherwise you plan to scrape the net scale, then executing the JavaScript on every net web page you go to is completely impractical. You’ll need to take a much more refined strategy to scraping the net. This performance is beneficial for net scraping as a result of lots of today’s trendy web pages make intensive use of JavaScript to dynamically populate the page. The downside this causes for regular web scraping spiders is most of them don’t execute this JavaScript code. Which prevents them from accessing all of the available information, limiting their capacity to extract all the obtainable knowledge. For this example, we'll be extracting data from quotes to scrape which is specifically made to practise internet scraping on. We'll then extract all of the quotes and their authors and store them in a CSV file. In addition to this, they supply CAPTCHA handling for you as well as enabling a headless browser so that you'll look like an actual person and never get detected as a web scraper. For more on its usage, check out my submit on net scraping with scrapy. In the primary a part of this collection, we introduced ourselves to the concept of net scraping utilizing two python libraries to attain this task. Web scraping utilizing Selenium and BeautifulSoup could be a useful tool in your bag of Python and information data tips, especially whenever you face dynamic pages and heavy JavaScript-rendered websites. This information has coated just some aspects of Selenium and web scraping. Our instruments might be Python and awesome packages like requests, BeautifulSoup, and Selenium. The third option is to make use of a self-service point-and-click on software program, corresponding to Mozenda. Selenium is a special software when compared to BeautifulSoup and Scrapy. It automates net browsers, and you should use it to carryout actions in browser environments in your behalf. With Selenium, you can pull out data from an HTML document 21 Lead Generation Software For B2B Businesses To Use in 2020 as you do with Javascript DOM API. Via Selenium’s API, you'll be able to truly export the underlying code to a Python script, which might later be used in your Jupyter Notebook or textual content editor of alternative.
- Selenium is an automation testing framework for internet functions/web sites which can additionally control the browser to navigate the website similar to a human.
- Webpages which might be generated dynamically can offer a sooner person expertise; the weather on the webpage itself are created and modified dynamically.
- These web sites are of nice benefit, but can be problematic once we need to scrape knowledge from them.
- In current years, there was an explosion of entrance-end frameworks like Angular, React, and Vue, which have gotten increasingly well-liked.
However, if there is a possibility that this scraper might want to develop or you’ll need to put in writing more spiders sooner or later you are higher off going with Scrapy. One small drawback about Scrapy is that it doesn’t handle JavaScript straight out of the field like Selenium. However, the staff at Scrapinghub has created Splash, an easy-to-combine, lightweight, scriptable headless browser specifically designed for web scraping. If speed isn’t an enormous concern or the scale of the net scraping isn’t huge, then utilizing Selenium to scrape the online will work, however it’s not perfect.
Just CBD makes a great relaxing CBD Cream for all your aches and pains! Visit our website to see the @justcbd collection! ???? #haveanicedaycbd #justcbd
— haveanicedaycbd (@haveanicedaycbd) January 23, 2020
-https://t.co/pYsVn5v9vF pic.twitter.com/RKJHa4Kk0J
In this walkthrough, we'll sort out net scraping with a barely totally different method using the selenium python library. We'll then store the results in a CSV file utilizing the pandas library. To figure which DOM components I wished Selenium extract, I used the Chrome Developer Tools which may be invoked by proper clicking a fund within the table and choosing Inspect Element. The HTML displayed right here incorporates exactly what we would like, what we didn’t see with our http request. Selenium literally “drives” your browser, so it could see anything you see whenever you right click on and examine factor in Chrome or Firefox.
Jewelry Stores Email List and Jewelry Contacts Directoryhttps://t.co/uOs2Hu2vWd
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Jewelry Stores Email List consists of contact details for virtually every jewellery store across all states in USA, UK, Europe, Australia, Middle East and Asia. pic.twitter.com/whSmsR6yaX
Selenium is an automation testing framework for internet functions/web sites which might also control the browser to navigate the web site identical to a human. Selenium makes use of an internet-driver package that can take management of the browser and mimic consumer-oriented actions to trigger desired events. The Selenium IDE permits you to easily examine elements of an online page by monitoring your interplay with the browser and providing alternate options you can use in your scraping. It additionally provides the chance to easily mimic the login expertise, which may overcome authentication points with certain websites. Finally, the export characteristic supplies a fast and easy way to deploy your code in any script or notebook you select.
In latest years, there has been an explosion of front-end frameworks like Angular, React, and Vue, which have gotten more and more in style. Webpages which are generated dynamically can provide a sooner consumer experience; the weather on the webpage itself are created and modified dynamically. These websites are of great profit, but could be problematic after we wish to scrape information from them. The simplest way to scrape these kinds of websites is by utilizing an automatic web browser, similar to a selenium webdriver, which may be managed by a number of languages, together with Python. If a login pop-up field arrives, Selenium IDE can kind in your credentials and transfer the process alongside. The Selenium-RC (remote-control) tool can control browsers through injecting its personal JavaScript code and can be utilized for UI testing. The automated internet scraping process described above completes rapidly. This permits me to show you a screen seize video of how briskly the method is. Many companies preserve software that allows non-technical business customers to scrape websites by constructing projects using a graphical consumer interface (GUI). Instead of writing customized code, customers merely load an internet web page into a browser and click to identify knowledge that ought to be extracted into a spreadsheet. First, particular person web sites may be difficult to parse for a wide range of causes.
Kick Start your B2B sales with the World's most comprehensive and accurate Sports Nutrition Industry B2B Marketing List.https://t.co/NqCAPQqF2i
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Contact all sports nutrition brands, wholesalers and manufacturers from all over the world in a click of a button. pic.twitter.com/sAKK9UmvPc
The variety of web pages you'll be able to scrape on LinkedIn is restricted, which is why I will solely be scraping key information points from 10 totally different person profiles. In some circumstances you might prefer to make use of a headless browser, which means no UI is displayed. But, in practice, individuals reported incompatibility issues where Selenium works correctly with Chrome or Firefox and generally fails with PhantomJS. I prefer to take away this variable from the equation and use an precise browser net driver. Static scraping was ok to get the list of articles, however as we saw earlier, the Disqus comments are embedded as an iframe factor by JavaScript. In what follows, you'll be working with Firefox, but Chrome might easily work too. My little instance makes use of the straightforward functionality offered by Selenium for net scraping – rendering HTML that is dynamically generated with Javascript or Ajax. Since Selenium is definitely a web automation tool, one could be rather more subtle by using it to automate a human navigating a webpage with mouse clicks and writing and submitting types. This could be a big time saver for researchers that depend on entrance-end interfaces on the web to extract knowledge in chunks. The alternative of library boils down to how the data in that exact webpage is rendered. The main problem associated with Scrapy is that it's not a newbie-centric tool. However, I had to drop the idea once I discovered it isn't newbie-friendly. One major setback of Scrapy is that it doesn't render JavaScript; you must ship Ajax requests to get knowledge hidden behind JavaScript occasions or use a third-celebration tool corresponding to Selenium. These internet apps normally have very restricted initial HTML and so scraping them with Nokogiri wouldn't deliver the specified results. In this tutorial, you will learn how the content material you see in the browser actually will get rendered and how to go about scraping it when needed. With Selenium, programming a Python script to automate an online browser is feasible. In this tutorial you’ll discover ways to scrape web sites with Selenium and ChromeDriver. You ought to now have a good understanding of how the Selenium API works in Python. If you want to know more about the other ways to scrape the net with Python don't hesitate to try our general python internet scraping information. If you employ a time.sleep() you will most likely use an arbitrary value. The full code could be requested by directly contacting me through LinkedIn. As we will want to extract information from a LinkedIn account we need to navigate to one of many profile URL's returned from our search throughout the ipython terminal, not through the browser. Next we might be extracting the inexperienced URLs of each LinkedIn users profile. And additionally make sure it's in your PATH, e.g. /usr/bin or /usr/local/bin. For more info relating to installation, please discuss with the hyperlink. Websites may load slowly or intermittently, and their knowledge could also be unstructured or discovered inside PDF files or photographs. This creates complexity and ambiguity in defining the logic to parse the location. Second, web sites can change without discover and in surprising ways. Web scraping tasks should be arrange in a approach to detect adjustments after which should be up to date to precisely collect the same information. Finally, websites may make use of applied sciences, corresponding to captchas, particularly designed to make scraping difficult. However, in addition to all this selenium turns out to be useful after we want to scrape data from javascript generated content material from a webpage. Nonetheless, each BeautifulSoup and scrapy are perfectly capable of extracting knowledge from a webpage. Selenium, then again, is a framework for testing net purposes. It permits for instantiating a browser instance utilizing a driver, then uses instructions to navigate the browser as one would manually. My go-to language for internet scraping is Python, as it has nicely-built-in libraries that can usually handle all of the functionality required. This would enable me to instantiate a “browser” – Chrome, Firefox, IE, and so forth. – then faux I was using the browser myself to achieve entry to the info I was in search of. And if I didn’t need the browser to really appear, I may create the browser in “headless” mode, making it invisible to any user. To be taught more about scraping advanced websites, please visit the official docs of Python Selenium. The major benefit Selenium has over the 2 is that it hundreds Javascript and can help you access data behind JavaScript with out essentially going by way of the pain of sending further requests your self. This had made Selenium not solely helpful to itself but to the other tools. Web scrapers that use both Scrapy or BeautifulSoup make use of Selenium in the event that they require knowledge that may only be available when Javascript information are loaded. You see how fast the script follows a hyperlink, grabs the info, goes again, and clicks the subsequent link. It makes retrieving the info from hundreds of links a matter of single-digit minutes. Before the code block of the loop is complete, Selenium needs to click on the again button in the browser. Luckily, the page player provides a "taking part in" class to the play button every time music is taking part in and removes it when the music stops. First, bandcamp designed their web site for people to enjoy utilizing, not for Python scripts to access programmatically. When you call next_button.click(), the actual net browser responds by executing some JavaScript code. Your first step, earlier than writing a single line of Python, is to install a Selenium supported WebDriver for your favorite internet browser. LinkedIn have since made its web site extra restrictive to net scraping tools. With this in mind, I decided to try extracting information from LinkedIn profiles simply to see how troublesome it would, especially as I am nonetheless in my infancy of learning Python. We have covered scraping static pages with fundamental instruments, which pressured us to spend a bit an excessive amount of time on trying to locate a selected component. While these approaches more-or-less work, the do have their limitations. For occasion, what occurs when a website depens on JavaScript, like in the case of Single Page Applications, or the infinite scroll pages? So, I determined to abandon my conventional strategies and have a look at a attainable tool for browser-based mostly scraping. Selenium is a framework which is designed to automate take a look at for web purposes. You can then write a python script to regulate the browser interactions mechanically such as hyperlink clicks and type submissions. Selenium is a framework designed to automate tests on your internet utility. Through Selenium Python API, you possibly can entry all functionalities of Selenium WebDriver intuitively. It provides Ad Verification Proxies a handy way to access Selenium webdrivers corresponding to ChromeDriver, Firefox geckodriver, etc. In order to harvest the feedback, we might want to automate the browser and work together with the DOM interactively. Web scraping has been used to extract data from websites virtually from the time the World Wide Web was born. We now have code that, if run, will open a browser and execute the instructions you specified by the IDE. In this section, we’ll cover the way to use the IDE code output, making changes with the assistance of the IDE, to scrape the data that you really want. There are fundamental features right here (e.g. rename), but this button is necessary for one cause, to export the code of the test.